Software and services for professional search. Review of programs for searching documents and data Internet resources for searching professional information
Alexey Kutovenko
Professional Internet Search
Introduction
Internet search is an important element of working on the Internet. It is unlikely that anyone knows for sure the exact number of web resources on the modern Internet. In any case, the count is in the billions. In order to be able to use the information needed at a given moment, no matter for work or entertainment purposes, you first need to find it in this constantly replenished ocean of resources. This is not an easy task at all, since information on the modern Internet is not structured, which creates problems in finding it. It is no coincidence that the peculiar “windows” into this information space Internet search engines have become
It is unlikely that among Internet users there will be people who have never used large universal search engines. The names Google, Yandex and a couple of other big machines are on everyone’s lips. They cope remarkably well with everyday Internet search tasks, and often users don’t even try to look for a replacement. At the same time, the number of Internet search engines in our time amounts to thousands. The reasons for such a variety of alternative machines have different roots. Some projects are trying to directly compete with global market leaders through careful work with national Internet resources. Others offer query capabilities not available from well-known search engines. A significant number of alternative engines specialize in searching for a certain topic area or a certain type of content, achieving impressive results in solving these problems. Be that as it may, the inclusion of such search engines in a user's own arsenal of Internet search tools can significantly improve its quality. However, there is one nuance here: you need to know about such machines and be able to use their capabilities.
We assume that readers of this book are already quite familiar with search techniques using universal search engines. It was so good that they felt the limitations associated with their use. Most likely, such people have already tried to look for and use certain additional tools. The printed word does not ignore the topic of Internet search: articles appear periodically and books are published. But their heroes, as a rule, are the same - several leading universal search engines. What makes this book different is that it attempts to cover the full range of modern search solutions. Here you will find descriptions and recommendations for using the best modern services aimed at solving the most common search problems. This book is for people who work a lot on the Internet and use the Network to find the information they need - be it business, study or hobby.
In order for an Internet search to be successful, two conditions must be met: queries must be well formulated and they must be asked in appropriate places. In other words, the user is required, on the one hand, to be able to translate his search interests into the language of the search query, and on the other hand, to have good knowledge of search engines, available tools search, their advantages and disadvantages, which will allow you to choose the most suitable search tools in each specific case.
Currently, there is no single resource that satisfies all Internet search requirements. Therefore, if you take your search seriously, you inevitably have to use different tools, using each in the most appropriate case.
There are many search tools available. They can be combined into several groups, each of which has certain advantages and disadvantages. The chapters of our book are devoted to the main groups of modern Internet search engines.
Chapter 1, “Universal Internet Search Engines,” is devoted to large universal systems for retrieving information on the Web. The main focus is on their most advanced instruments, which usually fall under the radar of the general public. A review of the capabilities of known machines gives us a kind of starting point and allows us to clearly imagine the scope of application of alternative search solutions.
Chapter 2, “Vertical Search,” introduces systems that specialize in specific topic areas or certain types content.
Chapter 3, “Metasearch,” covers meta search engines, capable of sending a request simultaneously to several Internet search engines, and then collecting and processing the results obtained in a single interface.
Chapter 4, “Semantic and Visual Internet Search Engines,” provides an overview of experimental systems that offer original user interfaces as well as interesting approaches to query processing.
Chapter 5, “Recommendation Machines,” introduces recently emerging search services, in English aptly named “Discovery Engines”, that is, “discovery machines”. With their help, you can process a number of queries that are too tough for other types of Internet search engines.
If no ready-made product suits you, you can create your own Internet search engine. Chapter 6, “Personal Search Engines,” is devoted to the creation of such personal machines.
Several chapters of our book are devoted to searching various types network content. Chapter 7, “Image Retrieval,” introduces current trends in Internet image retrieval as well as the capabilities of related experimental systems. Chapter 8, “Video Search,” offers an overview of the video search tools of the leading general-purpose Internet search engines, as well as the best specialized systems this direction.
Chapter 9, “Finding “Hidden” Content,” is an overview of systems that allow you to search for content that is “not seen” by universal search engines. Such “hidden” content includes, for example, torrents or files hosted on FTP servers and file hosting sites.
Chapter 10, “Search for Web 3.0,” introduces Internet search tools for data in Semantic Web formats.
The search doesn't end simple receipt results from one or another search engine. The last chapter of our book, Chapter 11, “Helper Programs,” is devoted to tools for processing and saving results.
Before starting a story about specific products, it makes sense to understand the classification of modern Internet search tools, as well as define the terms that are constantly found on the pages of our book.
The main Internet search tools can be divided into the following main groups:
Search engines;
Web directories;
Help Resources;
Local programs for searching the Internet.
The most popular search tools are search engines - the so-called Internet search engines (Search Engines). The top three leaders on a global scale are quite stable - Google, Yahoo! and Bing. In many countries, their own local search engines, optimized for working with local content, are added to this list. With their help, you can theoretically find any specific word on the pages of many millions of sites.
Despite many differences, all Internet search engines work on similar principles and with technical point vision systems consist of similar subsystems.
The first structural part of the search engine is special programs, used for automatic search and subsequent indexing of web pages. Such programs are usually called spiders, or bots. They look at the code of web pages, find links located on them, and thereby discover new web pages. There are also alternative way inclusion of the site in the index. Many search engines offer resource owners the opportunity to independently add a site to their database. However, the web pages are then downloaded, analyzed and indexed. Structural elements are identified in them, they are located keywords, their connections with other sites and web pages are determined. Other operations are also performed, the result of which is the formation of a search engine index database. This database is the second main element of any search engine. Currently, there is no single absolutely complete index database that would contain information about all Internet content. Since different search engines use different programs search for web pages and build their index using different algorithms, search engine index databases can vary significantly. Some sites end up being indexed by multiple search engines, but there is always a certain percentage resources included in the database of only one search engine. The presence of such an original and non-overlapping part of the index in each search engine allows us to draw an important practical conclusion: if you use only one search engine, even the largest one, you will definitely lose a certain percentage of useful links.
Professional Internet search requires specialized software, as well as specialized search engines and search services.
PROGRAMS
http://dr-watson.wix.com/home – the program is designed to study arrays of text information in order to identify entities and connections between them. The result of the work is a report on the object under study.
http://www.fmsasg.com/ - one of the best programs in the world for visualizing connections and relationships Sentinel Vizualizer. The company has completely Russified its products and connected hotline in Russian.
http://www.newprosoft.com/ – “Web Content Extractor” is the most powerful, easy-to-use software for extracting data from web sites. It also has an effective Visual Web spider.
SiteSputnik – a software package that has no analogues in the world, allowing you to search and process its results on the Visible and Invisible Internet, using all the search engines necessary for the user.
WebSite-Watcher – allows you to monitor web pages, including password-protected ones, monitoring forums, RSS feeds, news groups, local files. Possesses powerful system filters. Monitoring is carried out automatically and is delivered in a user-friendly form. A program with advanced functions costs 50 euros. Constantly updated.
http://www.scribd.com/ is the most popular platform in the world and increasingly used in Russia for posting various kinds of documents, books, etc. for free access with a very convenient search engine for titles, topics, etc.
http://www.atlasti.com/ is the most powerful and effective tool for qualitative information analysis available to individual users, small and even medium-sized businesses. The program is multifunctional and therefore useful. It combines the ability to create a unified information environment for working with various text, tabular, audio and video files as a single whole, as well as tools for qualitative analysis and visualization.
Ashampoo ClipFinder HD – an ever-increasing share of the information flow comes from video. Accordingly, competitive intelligence officers need tools that allow them to work with this format. One of such products is the presented free utility. It allows you to search for videos based on specified criteria on video file storage sites such as YouTube. The program is easy to use, displays all search results on one page with detailed information, titles, duration, time when the video was uploaded to the storage, etc. There is a Russian interface.
http://www.advego.ru/plagiatus/ – the program was made by SEO optimizers, but is quite suitable as an Internet intelligence tool. Plagiarism shows the degree of uniqueness of the text, the sources of the text, and the percentage of text match. The program also checks the uniqueness of the specified URL. The program is free.
http://neiron.ru/toolbar/ – includes an add-on for combining Google and Yandex search, and also allows for competitive analysis based on assessing the effectiveness of sites and contextual advertising. Implemented as a plugin for FF and GC.
http://web-data-extractor.net/ is a universal solution for obtaining any data available on the Internet. Setting up data cutting from any page is done in a few mouse clicks. You just need to select the data area that you want to save and Datacol will automatically select a formula for cutting out this block.
CaptureSaver is a professional Internet research tool. Simply irreplaceable working programm, allowing you to capture, store and export any Internet information, including not only web pages, blogs, but also RSS news, email, images and much more. It has the widest functionality, an intuitive interface and a ridiculous price.
http://www.orbiscope.net/en/software.html – web monitoring system at more than affordable prices.
http://www.kbcrawl.co.uk/ – software for work, including on the “Invisible Internet”.
http://www.copernic.com/en/products/agent/index.html – the program allows you to search using more than 90 search engines, using more than 10 parameters. Allows you to combine results, eliminate duplicates, block broken links, and show the most relevant results. Comes in free, personal and professional versions. Used by more than 20 million users.
Maltego is a fundamentally new software that allows you to establish the relationship of subjects, events and objects in real life and on the Internet.
SERVICES
new – web browser with dozens of pre-installed tools for OSINT.
– an effective search engine-aggregator for finding people on major Russian social networks.
https://hunter.io/ – efficient service to detect and verify email.
https://www.whatruns.com/ is an easy to use yet effective scanner to discover what is and isn't working on a website and what its security holes are. Also implemented as a plugin for Chrom.
https://www.crayon.co/ is an American budget platform for market and competitive intelligence on the Internet.
http://www.cs.cornell.edu/~bwong/octant/ – host identifier.
https://iplogger.ru/ – simple and convenient service to determine someone else's IP.
http://linkurio.us/ is a powerful new product for economic security workers and corruption investigators. Processes and visualizes huge amounts of unstructured information from financial sources.
http://www.intelsuite.com/en – English-language online platform for competitive intelligence and monitoring.
http://yewno.com/about/ – first current system translating information into knowledge and visualizing unstructured information. Currently supports English, French, German, Spanish and Portuguese.
https://start.avalancheonline.ru/landing/?next=%2F – forecasting and analytical services by Andrey Masalovich.
https://www.outwit.com/products/hub/ – a complete set of stand-alone programs for professional work in web 1.
https://github.com/search?q=user%3Acmlh+maltego – extensions for Maltego.
http://www.whoishostingthis.com/ – search engine for hosting, IP addresses, etc.
http://appfollow.ru/ – analysis of applications based on reviews, ASO optimization, positions in tops and search results for the App Store, Google Play and Windows Phone Store.
http://spiraldb.com/ is a service implemented as a plugin for Chrom, which allows you to get a lot of valuable information about any electronic resource.
https://millie.northernlight.com/dashboard.php?id=93 - free service, collecting and structuring key information by industry and company. It is possible to use information panels based on text analysis.
http://byratino.info/ – collection of factual data from publicly available sources on the Internet.
http://www.datafox.co/ – CI platform collects and analyzes information on companies of interest to clients. There is a demo.
https://unwiredlabs.com/home - a specialized application with an API for searching by geolocation of any device connected to the Internet.
http://visualping.io/ – a service for monitoring websites and, first of all, the photographs and images available on them. Even if the photo only appears for a second, it will be in the subscriber's email. Has a plugin for Google Chrome.
http://spyonweb.com/ is a research tool that allows for in-depth analysis of any Internet resource.
http://bigvisor.ru/ – the service allows you to track advertising companies for certain segments of goods and services, or specific organizations.
http://www.itsec.pro/2013/09/microsoft-word.html – instructions for use by Artem Ageev Windows programs for competitive intelligence needs.
http://granoproject.org/ is an open source tool source code for researchers who track networks of connections between individuals and organizations in politics, economics, crime, etc. Allows you to connect, analyze and visualize information obtained from various sources, as well as show significant connections.
http://imgops.com/ – service for extracting metadata from graphic files and working with them.
http://sergeybelove.ru/tools/one-button-scan/ – a small online scanner for checking security holes in websites and other resources.
http://isce-library.net/epi.aspx – service for searching primary sources using a fragment of text in English
https://www.rivaliq.com/ is an effective tool for conducting competitive intelligence in Western, primarily European and American markets for goods and services.
http://watchthatpage.com/ is a service that allows you to automatically collect new information from monitored Internet resources. The service is free.
http://falcon.io/ is a kind of Rapportive for the Web. It is not a replacement for Rapportive, but provides additional tools. In contrast, Rapportive provides a general profile of a person, as if glued together from data from social networks and mentions on the web. http://watchthatpage.com/ - a service that allows you to automatically collect new information from monitored resources on the Internet. The service is free.
https://addons.mozilla.org/ru/firefox/addon/update-scanner/ – add-on for Firefox. Monitors web page updates. Useful for websites that do not have news feeds (Atom or RSS).
http://agregator.pro/ – aggregator of news and media portals. Used by marketers, analysts, etc. to analyze news flows on certain topics.
http://price.apishops.com/ – an automated web service for monitoring prices for selected product groups, specific online stores and other parameters.
http://www.la0.ru/ is a convenient and relevant service for analyzing links and backlinks to an Internet resource.
www.recordedfuture.com is a powerful tool for data analysis and visualization, implemented as an online service built on cloud computing.
http://advse.ru/ is a service with the slogan “Find out everything about your competitors.” Allows you to obtain competitors' websites in accordance with search queries and analyze competitors' advertising campaigns in Google and Yandex.
http://spyonweb.com/ – the service allows you to identify sites with the same characteristics, including those using the same statistics service identifiers Google Analytics, IP addresses, etc.
http://www.connotate.com/solutions – a line of products for competitive intelligence, managing information flows and converting information into information assets. It includes both complex platforms and simple, cheap services that allow for effective monitoring along with information compression and obtaining only the necessary results.
http://www.clearci.com/ - competitive intelligence platform for businesses of various sizes from start-ups and small companies to Fortune 500 companies. Solved as saas.
http://startingpage.com/ is a Google add-on that allows you to search on Google without recording your IP address. Fully supports all Google search capabilities, including in Russian.
http://newspapermap.com/ is a unique service that is very useful for a competitive intelligence officer. Connects geolocation with an online media search engine. Those. you select the region you are interested in, or even a city, or language, see the place on the map and a list of online versions of newspapers and magazines, click on the appropriate button and read. Supports Russian language, very user-friendly interface.
http://infostream.com.ua/ is a very convenient news monitoring system “Infostream”, distinguished by a first-class selection and quite accessible to any wallet, from one of the classics of Internet search, D.V. Lande.
http://www.instapaper.com/ is a very simple and effective tool for saving the necessary web pages. Can be used on computers, iPhones, iPads, etc.
http://screen-scraper.com/ – allows you to automatically extract all information from web pages, download the vast majority of file formats, and automatically enter data into various forms. Saves downloaded files and pages in databases, performs many other extremely useful functions. Works on all major platforms, has fully functional free and very powerful professional versions.
http://www.mozenda.com/ - having several tariff plans and a web service of multifunctional web monitoring and delivery of information necessary for the user from selected sites, available even to small businesses.
http://www.recipdonor.com/ - the service allows you to automatically monitor everything that happens on competitors' websites.
http://www.spyfu.com/ – and this is if your competitors are foreign.
www.webground.su is a service for monitoring the Runet created by Internet search professionals, which includes all major providers of information, news, etc., and is capable of individual monitoring settings to suit the user’s needs.
SEARCH ENGINES
https://www.idmarch.org/ is the best search engine for the world archive of pdf documents in terms of quality. Currently, more than 18 million pdf documents have been indexed, ranging from books to secret reports.
http://www.marketvisual.com/ is a unique search engine that allows you to search for owners and top management by full name, company name, position, or a combination thereof. The search results contain not only the objects you are looking for, but also their connections. Designed primarily for English-speaking countries.
http://worldc.am/ is a search engine for freely accessible photographs linked to geolocation.
https://app.echosec.net/ is a publicly available search engine that describes itself as the most advanced analytical tool for law enforcement and security and intelligence professionals. Allows you to search for photos posted on various sites, social platforms and social networks in relation to specific geolocation coordinates. There are currently seven data sources connected. By the end of the year their number will be more than 450. Thanks to Dementy for the tip.
http://www.quandl.com/ – search engine for seven million financial, economic and social bases data.
http://bitzakaz.ru/ – search engine for tenders and government orders with additional paid functions
Website-Finder - makes it possible to find sites that Google does not index well. The only limitation is that it only searches 30 websites for each keyword. The program is easy to use.
http://www.dtsearch.com/ is a powerful search engine that allows you to process terabytes of text. Works on desktop, web and intranet. Supports both static and dynamic data. Allows you to search in all MS Office programs. The search is carried out using phrases, words, tags, indexes and much more. The only federated search engine available. It has both paid and free versions.
http://www.strategator.com/ – searches, filters and aggregates information about the company from tens of thousands of web sources. Searches in the USA, Great Britain, major EEC countries. It is highly relevant, user-friendly, and has free and paid options ($14 per month).
http://www.shodanhq.com/ is an unusual search engine. Immediately after his appearance, he received the nickname “Google for hackers.” It does not search for pages, but determines IP addresses, types of routers, computers, servers and workstations located at a particular address, and traces chains DNS servers and allows you to implement many others interesting features for competitive intelligence.
http://search.usa.gov/ is a search engine for websites and open databases of all US government agencies. The databases contain a lot of practical useful information, including for use in our country.
http://visual.ly/ – today visualization is increasingly used to present data. This is the first infographic search engine on the Web. Along with the search engine, the portal has powerful data visualization tools that do not require programming skills.
http://go.mail.ru/realtime – search for discussions of topics, events, objects, subjects in real or customizable time. The previously highly criticized search in Mail.ru works very effectively and provides interesting, relevant results.
Zanran is just launched, but already working great, the first and only search engine for data that extracts it from PDF files, EXCEL tables, data on HTML pages.
http://www.ciradar.com/Competitive-Analysis.aspx is one of the world's best information retrieval systems for competitive intelligence on the deep web. Retrieves almost all types of files in all formats on the topic of interest. Implemented as a web service. The prices are more than reasonable.
http://public.ru/ – Effective search and professional analysis of information, media archive since 1990. The online media library offers a wide range information services: from access to electronic archives of publications of Russian-language media and ready-made thematic press reviews to individual monitoring and exclusive analytical research carried out based on press materials.
Cluuz is a young search engine with ample opportunities for competitive intelligence, especially on the English-language Internet. Allows you not only to find, but also to visualize and establish connections between people, companies, domains, e-mails, addresses, etc.
www.wolframalpha.com – the search engine of tomorrow. In response to a search request, it provides statistical and factual information available on the request object, including visualized information.
www.ist-budget.ru – universal search in databases of government procurement, tenders, auctions, etc.
Checking a nickname across dozens of services at a time, counting reposts on Facebook and visualizing Twitter account connections.
Social media content analysis is a hot topic among startups. More and more services for searching posts and people appear every year. But many of them either disappear quickly, are available in an unfinished state, or are expensive to use.
This material contains a few of them that allow you to quickly and freely get really useful or simply interesting information.
1. Search for profiles
Search system Snitch allows you to search for a person’s profile in four dozen services, including the websites of the world’s leading universities and the US criminal database:
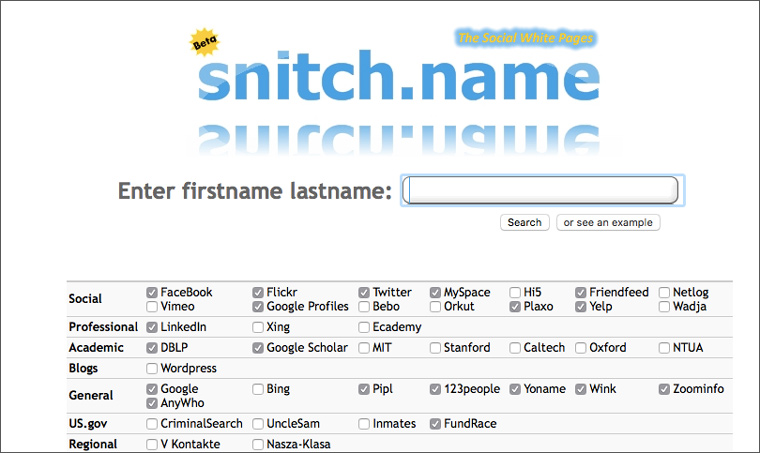
Unfortunately, some of the sites for which you can check boxes no longer work. For example, Google Uncle Sam, closed 5 years ago. But despite this and other Snitch jambs - useful service, which allows you to significantly save time when searching for information about a person.
If for some service a blank screen is displayed instead of blocks with search results, then to view them you need to follow the link Open a new window:
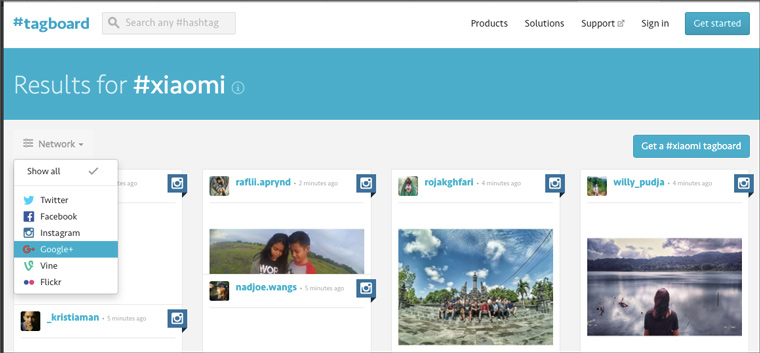
2. Search for hashtags
It's very easy to use. You need to enter the desired hashtag into the search form and in a second a list of recent posts tagged with it in six social networks will appear:
3. Analysis of recent tweets
The service allows you to get a list of the last hundred tweets containing the search word, hashtag or account name. And also find out some analytical information about the people who made these tweets and the time they were created:

Let's say you want to identify which user caused an unusually high number of clicks to an article from Twitter. We look at the latest 100 tweets and see which of the people who mentioned the original concept have the most followers:

Owners paid subscription A large number of tweets are available for analysis:

4. Twitter account analysis
On Mentionapp you can enter the account name and get information about it (who retweets most often, what hashtags it uses, etc.) in the form of a connection diagram:

5. Search for tweets on the map
If you click on any place on the map, you can read the latest tweets made nearby:

6. Number of mentions on social networks
Sharedcount helps to evaluate the popularity of an article/site on social networks. You enter the URL and after a couple of seconds there are statistics of mentions on Facebook, Google+, Pinterest, LinkedIn and Stumble Upon:

7. Search the forums
Boardreader is a search engine for forums and message boards:
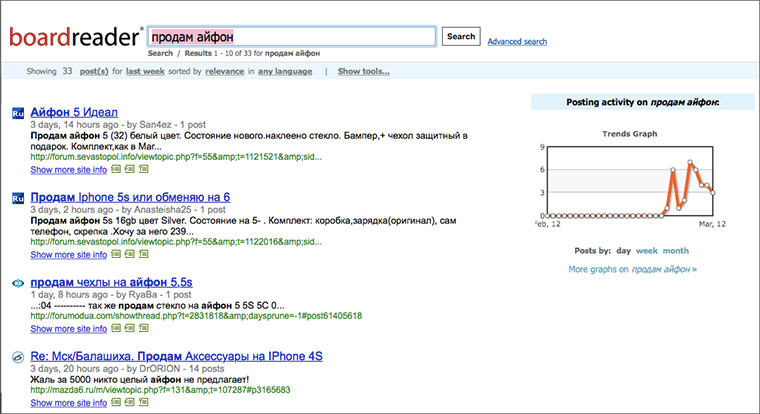
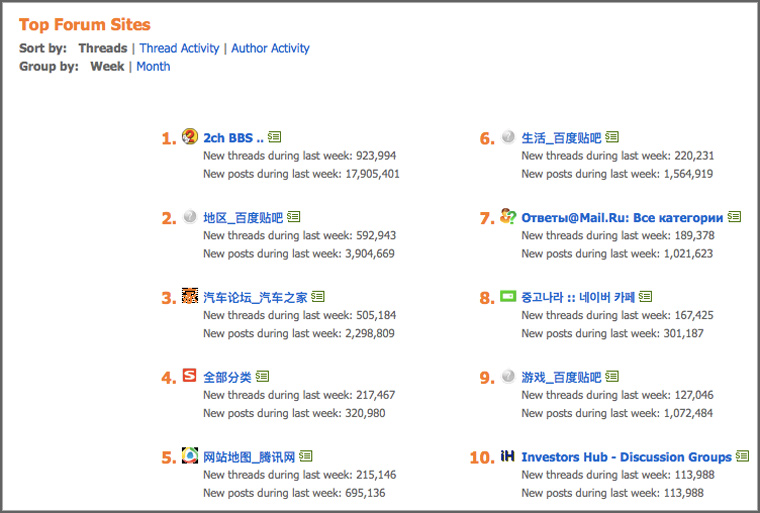
An assessment of the scale of the disaster showed that there are almost 4 responses on this portal per resident of Russia.
8. We break through the login via social networks
We go to knowem.com and enter the person’s nickname. In response, we receive information about which services it is registered on:

9. Determine a person’s name by email
If you are still looking for people by typing their email addresses into Google, then you should give up this method. After all, there is pipl.com. You enter your email (nickname) and get a list of profiles on social networks:

The information is not always accurate or complete, but the service is extremely useful.
That's all. It was worth talking about Socialmention (unfinished analysis of reviews), Yomapic (search for photos from VK and Instagram on a map) and yandex.
By mid-2015, the global Internet had already connected 3.2 billion users, that is, almost 43.8% of the planet’s population. For comparison: 15 years ago, only 6.5% of the population were Internet users, that is, the number of users has increased more than 6 times! But what is more impressive is not the quantitative, but the qualitative indicators of the expansion of the implementation of Internet technologies in various areas of human activity: from global communications of social networks to household Internet things. Mobile Internet provided users with the opportunity to be online outside the office and at home: on the road, outside the city in nature.
Currently, there are hundreds of systems for searching information on the Internet. The most popular of them are available to the vast majority of users because they are free and easy to use: Google, Yandex, Nigma, Yahoo!, Bing..... For more experienced users, “advanced search” interfaces, specialized searches “by social networks", according to news flows and purchase and sale advertisements... But all these wonderful search engines have a significant drawback, which I already noted above as an advantage: they are free.
If investors invest billions of dollars in the development of search engines, then a completely appropriate question arises: where do they make money?
And they make money, in particular, by providing in response to user requests not so much information that would be useful from the user’s point of view, but that which the owners of search engines consider useful for the user. This is done by manipulating the order in which lists of answers are issued to search queries users. Here there is open advertising of certain Internet resources, and hidden manipulation of the relevance of answers based on the commercial, political and ideological interests of the owners of search engines.
Therefore, among professional specialists in searching for information on the Internet, the problem of pertinence of search engine results is very relevant.
Pertinence is the correspondence of documents found by an information retrieval system to the information needs of the user, regardless of how fully and how accurately this information need is expressed in the text of the information request itself. This is the ratio of the amount of useful information to the total amount of information received. Roughly speaking, this is search efficiency.
Specialists carrying out qualified searches for information on the Internet need to make certain efforts to filter search results, weeding out unnecessary information “noise”. And for this, professional-level search tools are used.
One of these professional systems- Russian program FileForFiles & SiteSputnik (SiteSputnik).
Developer Alexey Mylnikov from Volgograd.
"The FileForFiles & SiteSputnik program (SiteSputnik) is designed to organize and automate professional search, collection and monitoring of information posted on the Internet. Particular attention is paid to obtaining new incoming information on topics of interest. Several information analysis functions have been implemented."
Monitoring and categorization of information flows
First a few words about monitoring information flows, a special case of which is monitoring of media and social networks:
- the user specifies Sources that may contain necessary information, and Rules for selecting this information;
- the program downloads fresh links from Sources, frees their content from garbage and repetitions, and arranges them into Sections according to the Rules.
To see live a simple but real monitoring process, which involves 6 sources and 4 headings:- open the Demo version of the program;
- then, in the window that appears, click on the button Together;
- and when WebsiteSputnik will carry out this Project in real time, you:
— in the “Clean Stream” list you will see all the new information from Sources,
— in the “Post-request” section - only economic and financial news that satisfies the rule,
- in the Headings "About the President", "About the Premiere" and "Central Bank", - information related to the relevant objects.
In real Projects, you can use almost any number of Sources and Rubrics.
You can create your first working Projects in a few hours, and improve them during operation.
The described information processing is available in the SiteSputnik Pro+News package and higher.
2. Simple and batch search, information collection
To get acquainted with the possibilities SiteSputnik Pro(basic version of the program) :
- open the Demo version of the program;
- enter your first request, for example, your full name, as I did:
and click on the button Search.
- The program (see the sign that SiteSputnik built) will poll in a few seconds 7 sources, will open in them 24 search pages, will find 227 relevant links, will remove duplicate links and from the remaining 156 unique list of links "An association".
Total: number of unique links - 156 , duplicate links - 46 %.
Name
Source
Ordered
pages
Downloaded
pages
Found
links
Time
search
Efficiency
search
Links
New
Efficiency
NewYandex 5 5 50 0:00:05 32% 0 0 5 5 44 0:00:03 28% 0 0 Yahoo 5 5 50 0:00:05 32% 0 0 Rambler 5 4 56 0:00:07 36% 0 0 MSN (Bing) 5 3 23 0:00:04 15% 0 0 Yandex.Blogs 5 1 1 0:00:01 1% 0 0 Google.Blogs 5 1 3 0:00:01 2% 0 0 Total: 35 24 227 0:00:26 — 0 0 - (! ) Repeat your request after a few hours or days, and you will see only new links that appeared in the Sources for this period of time. In the last two columns of the table you can see how many new links each Source brought and its efficiency in terms of “novelty”. When a query is executed multiple times, a list containing only new links , is created relative to all previous executions of this request. It would seem elementary and required function, but the author is not aware of any program in which it is implemented.
- (!! ) The described capabilities are supported not only for individual requests, but also for entire request packets :
The package that you see consists of seven different queries that collect information about Vasily Shukshin from several Sources, including search engines, Wikipedia, exact search in Yandex news, metasearch and search for mentions on TV and radio stations. To the script TV and Radio includes: "Channel One", "TV Russia", NTV, RBC TV, "Echo of Moscow", radio company "Mayak", ... and other sources of information. Each Source has its own search or browsing depth in pages. It is listed in the third column.
Batch search allows you to perform comprehensive searches with one click collection of information on a given topic.
Separate list new links, upon repeated executions of the package, will contain only links that were not previously found.
Remember what and when you asked the Internet and what it answered you No need- everything is automatically saved in libraries and in program databases.
I repeat that the capabilities described in this paragraph are fully included in the package SiteSpunik Pro.
More details in the instructions: SiteSputnik Pro for beginners.
3. Objects and search monitoring
Quite often the User is faced with the following task. You need to find out what is on the Internet about a specific object: a person or a company. For example, when hiring a new employee or when a new counterparty appears, you always know the full name, company name, telephone numbers, INN, OGRN or OGRNIP, you can also take ICQ, Skype and some other data. Next, using a call to a special program function WebsiteSputnik "Collecting information about the object" (equipment SiteSputnik Pro+Objects):You enter the data that you know, and with one click of the mouse you carry out accurate And full search for links containing specified information. The search is performed on several search engines at once, using all the details at once, using several possible combinations of recording details at once: remember how you can write down a phone number in different ways. After a certain period of time, without doing boring routine work, you will receive a list of links, cleared of repetitions and, most importantly, ordered by relevance to the object you are looking for. Relevance (significance) is achieved due to the fact that the first in the SiteSputnik search results will be those links on which large quantity the details you specified, and not those that moved up the search engine results of the Webmaster.
Important .
The SiteSputnik program is better than other programs at extracting real, but not official information about the Object. For example, in the official database mobile operator it may be recorded that the phone belongs to Vasily Terekhin, but in reality this phone contains information that Alexander sold a Ford Focus car in 2013, which is additional information for thought.Search monitoring .
Search monitoring means the following. If you need to track the appearance new links, by a given object or arbitrary package of queries, then you just need to periodically repeat the corresponding search. Same as for a simple request, program SiteSputnik will create a "New" list, in which it will place only those links that were not found in any of the previous searches.Search monitoring interesting not only in itself. It may be involved in monitoring the media, social networks and other news sources, which was mentioned above in paragraph 1. Unlike other programs, in which it is possible to obtain new information only from RSS feeds, in the program WebsiteSputnik can be used for this searches built into websites And search engines . Also possible emulation (self-creation) several RSS feeds With arbitrary pages, moreover, emulation of RSS feed by request and even a batch of requests.
- To get the most out of the program, use its main functions, namely:
- request packages, packages with parameters, use the Assembler (assembler), the "Analytical merging" operation of the results of several tasks, if necessary, apply basic search functions on the invisible Internet;
- connect your sources to the information sources built into the program : other search engines and searches built into sites, existing RSS feeds created by you own RSS feeds With arbitrary pages, use the search function for new sources;
- take advantage of opportunities the following types monitoring: Media, social networks and other sources, monitoring comments to news and messages, track the appearance of new information on existing pages;
- engage Categories , External functions, Task Scheduler, mailing list, multiple computers, Project Instructor, install alarm To notify you of the occurrence of significant events, use the other functions listed below.
4. SiteSputnik program (SiteSputnik): options and features
- Program SiteSputnik is constantly improving in the following areas: "I need to find everything and with a guarantee".
"Interrogation Software for the Internet", - another definition of the User for assigning the program.A. Functions for searching and collecting information.
. Request package - execution of several queries at once, combining search results or separately. When generating the combined result, repeatedly found links are removed. More details about packages can be found in the introduction to SiteSputnik, and visually in the video: a joint And separate execution of requests. There are no analogues in domestic and foreign developments.
. Parameter packages. Any queries and query packages designed to solve standard search tasks, for example, search by phone number, full name or e-mail, - can be parameterized, saved and executed from a library of ready-made queries with the substitution of actual (needed) parameter values. Each package with parameters is its own special advanced search form . It can use not one, but several search engines. You can create forms that are very complex in their functional purpose. It is extremely important that forms can be created by users themselves, without the participation of the program author or programmer. This is written very simply in the instructions, more details in a separate publication about search parameterization and on the forum, clearly in the video: search for all options for recording a number at once mobile phone and according to several options for recording the address Email. There are no analogues.
. Assembler NEW- assembling a search task from several ready-made ones : requests, request packages and parameter packages. Packages may contain other packages in their text. The depth of nesting of packages is unlimited. You can create several search tasks, for example, about several legal and individuals, and complete these tasks simultaneously. More details on the forum and in a separate publication about Assembler, clearly at video. There are no analogues.
. Metasearch - execution of a specific request simultaneously at a given “depth” of search for each of them. Metasearch is possible using built-in search engines, which include Yandex, Rambler, Google, Yahoo, MSN (Bing), Mail, Yandex and Google blogs, and connected search tools. Working with multiple search engines looks like you're working with one search engine . Re-found links are deleted. Visually metasearch on three connected social networks: VKontakte, Twitter and Youtube - shown on video.
. Metasearch on the site - combining site search in Google, Yahoo, Yandex, MSN (Bing). Clearly on video.
. Metasearch in office documents - combining search in files PDF format, XLS, DOC, RTF, PPT, FLASH in Google, Yahoo, Yandex, MSN (Bing). You can choose any combination of file formats.
. Metasearch for cache copies links in Yandex, Google, Yahoo, MSN (Bing). A list is compiled, each item of which contains all the snippets found for each link by each search engine. There are no analogues.
. Deep Search for Yandex, Google and Rambler allows you to combine into one list all links from the regular search and all links, respectively, from the lists “More from the site”, “Additional results from the site” and “Search on the site (Total...)”. Read more about deep search on the forum. There are no analogues.
. Accurate and complete search . This means the following. On the one hand, each query can be executed on that and only on the source in whose query language it is written. This exact search. On the other hand, there can be an arbitrary number of such requests and sources. This provides full search. Read more in a separate post about procedural search. There are no analogues.
. Searching the Invisible Internet .
It includes the following basic features:
B. Information monitoring functions.A special package of requests that can be improved by the User,
- search for invisible links using a spider,
- search for invisible links in the vicinity of a visible link or folder by “image and likeness”,
- special searches for open folders,
- search for invisible links and folders with standard names using special dictionaries,
- use of your own searches built into sites.More details in a separate publication on SiteSputnik Invisible. Basic functions“well known in narrow circles,” but the method of their application has no analogues. The essence of this method is to build a site map visible from the Internet (in other words, materialize visible internet), and only on the basis of visible links and search for invisible links in relation to them. Searching for already visible links using “invisible” methods is not carried out.
. Monitoring for appearance on the Internet new links on a given topic. Monitor appearance new links can be used using integers request packets , which involve any of the search methods mentioned above, rather than individual search engine front pages. Implemented union and intersection new links from multiple separate searches. More details in the publication on monitoring (see § 1) and on the forum. There are no analogues.
. Collective information processing . Creation corporate or professional network for collective collection, monitoring and analysis of information. The participants and creators of such a network are employees of the corporation, members of a professional community or interest groups. The geographic location of the participants does not matter. More details in a separate publication about organizing a network for collective collection, monitoring and analysis of information.
. Monitoring links (web pages) to detect changes in their content (content). Beta version. Found changes are highlighted with color and special symbols. More details in a separate publication on monitoring (see § 2 and 3).
IN. Information analysis functions.
. Categories of materials already described above. More details can be found in a separate publication about Rubrics. Rules for entering Rubrics allow you to specify keywords and the distance between them, set logical “AND”, “OR” and “NOT”, apply a multi-level bracket structure and dictionaries (insert files) to which logical operations can be applied.
. VF technology - almost arbitrary expansion of the possibility of categorizing materials through the implementation of external functions that are organically integrated into the Rules for entering Rubrics and can be implemented by the programmer independently without the participation of the program author.
. Numerical analysis occupancy of Rubriks, installation alarm and notification of the occurrence of significant events by highlighting the Rubrics in color and/or sending an alarm report by e-mail.
. Factual relevance. There is an option to arrange the links in order close to significance these links in relation to the problem being solved, bypassing the tricks of webmasters who use various ways increasing website rankings in search engines. This is achieved by analyzing the results of executing several “diverse” queries on a given topic. In the literal sense of the word, links containing maximum required information . Read more in the description of how to find the optimal supplier and on the forum. There are no analogues.
. Calculating Object Relationships - search for links, resources (sites), folders and domains on which objects are simultaneously mentioned. The most common objects are people and firms. To search for connections, all program tools mentioned on this page can be used SiteSputnik, which significantly increases the efficiency of the work you do. The operation is performed on any number of objects. More details in the introduction to the program, as well as in the description new feature"objects and their connections." There are no analogues.
. Formation, integration and intersection of information flows on a variety of topics, comparison of threads. More details in a separate post on threads.
. Building web maps sites, resources, folders and searched objects based on those found on the Internet when Google help, Yahoo, Yandex, MSN (Bing) and Altavista links belonging to the site. Experts can find out: is it visible "extra" information from the Internet on their websites, as well as research competitors’ websites on this subject. Web sitemap is materialization of the visible internet . More details in a separate publication about building web maps, visually at video. There are no analogues.
. Finding new sources of information on a given topic, which can then be used to track the emergence of new relevant information. More details at.
G. Service functions.
. Task Scheduler provides work Scheduled: performs in specified time specified program functions. More details in a separate publication about the Planner.
. Project Instructor NEW- this is an assistant creation and maintenance Projects for searching, collecting, monitoring and analyzing information (categorization and signaling). More details on the forum.
. Automatic archiving. IN databases All the results of your work are automatically remembered, namely: requests, request packages, search and monitoring protocols, any other of the above functions and the results of their execution. Can structure work on topics and subtopics.
. Database includes sorting, simple search and custom search by SQL query. For the latter, there is a wizard for composing SQL queries. Using these tools, you can find and review the work you did yesterday, last month, a year ago, define a topic as a search criterion, or set another search criterion based on the contents of the database.
. Technical limitations search engines. Some limitations, such as the length of the query string, can be overcome. It ensures the execution of not one, but several queries, combining search results or separately. You can read about a way to overcome violation of the law of additivity for major search engines. For one word or one phrase enclosed in quotes, a case-sensitive search in search engines is implemented, in particular, search by abbreviation.
Built-in browser . Navigator by page. Multicolor marker to highlight key and arbitrary words. Bilisting and N-listing from generated documents.
. Unloading news feeds into a table view focused on import in Excel, MySQL, Access, Kronos and other Applications.
5. Installation and launch of the Program, computer requirements.
To install and run the program:
- Download the file, copy the FileForFiles folder from it to your HDD, for example, on D:\;
- Demo version of the program will be installed and it will open.
The program will work on any computer on which it is installed Windows any versions.The machines must work.
People must think.The “Professional Internet Search” course is a convenient way to learn how to competently and effectively search and find the necessary information on the Internet.
What's happened professional search?
Internet paradox is that information becomes more and more More, but find necessary information becomes it's getting harder. Professional search is efficient search necessary And reliable information.
In the modern world, information becomes capital, and the Internet becomes a convenient means of obtaining it, which is why the ability to find valuable information characterizes a person as high class professional. A professional search should always be effective. Moreover, during the search, professionals not only look for the place where the information is stored, but also evaluate the authority of the resource, relevance, accuracy, and completeness of the published information. Internet heuristics help us with this - a set of useful search rules, criteria for selecting and evaluating network information.What will you learn and what will you learn?
Have you been looking and couldn't find it? Then the course will be extremely useful to you. You'll get comprehensive search instructions something that is already on the Internet, but at first glance it seems that it is simply impossible to find... Perhaps! You will learn, how to search to find! Each lesson is based on a combination of knowledge and experience, all received knowledge is tested in action.
During the course classes You will learn how the modern Internet develops and how it spreads electronic information, how directories are created and how search engines work, why metasearch engines are needed and where the “hidden” web came from, how forums differ from blogs and what fundraising is.
During workshops You will learn use the query language correctly, select keywords wisely, find information on the “hidden” web, find the necessary images and files, evaluate public opinion in the blogosphere, search personal information, and most importantly - to correctly assess the reliability, relevance and completeness of the information found.
The Internet search course will allow you to significantly develop your cognitive, information and communication abilities.
What topics are covered in the Professional Search course?
The goal of the course is to teach in one month the possibilities and subtleties of modern search for professional information on the Internet.
Each lesson (module) includes lecture, seminar in a forum format, test to master the material covered, as well as several exercises and search tasks.
The updated course will feature weekly one-hour webinars - interactive virtual online seminars dedicated to discussing the key tasks of professional Internet search.
Each training module is equipped useful additional materials on course topics and handouts convenient for printing.
The thematic plan of the course consists of 10 interrelated modules:
1. Internet: history, technology and Internet research.
2. Information search. Search directories.
3. Information retrieval systems. IPS close-up (Google, Yandex and others).
4. Metasearch engines and programs.
5. Internet Help Desk: factual search in encyclopedias, reference books, dictionaries.
6. Bibliographic search: libraries, catalogs, programs.
7. Documentary search: electronic documents, electronic libraries, electronic journals.
8. "Hidden" Web: Search multimedia, databases, knowledge bases and files.
9. Search news(blogs and forums), contacts, institutions, fundraising.
10. Information Retrieval Strategies: Generalization of Internet heuristics skills.
Why is the course distance learning?
The distance course has a whole several advantages.
Firstly, each lesson is allocated not one or two academic hours per week, but whole week. You can master and assimilate lecture material, perform exercises and search tasks without haste.
Secondly, distance learning course interactive. This means that you can always ask, clarify, find out from the teacher what you think is important. Your question will not go unanswered, and complex search tasks can be discussed as a group to evaluate each skill in comparison.
Thirdly, you can study at a time convenient for you and you won’t have to waste time traveling to classes. Moreover, you can study anywhere in the world where there is access to the Internet.
What is par for the course?
The “Internet heuristics” course will last one month and will consist of 10 modules, each module consists of “quanta” lessons - they allow you to maintain the pace necessary for mastering new material). Price of each module – only 300 rubles, for all classes you will pay only 3000 rubles. Please note that you do not have to buy additional textbooks; the course is fully provided with all the necessary educational materials. If you successfully complete the course, you will receive a Moscow State University certificate for completing the “Professional Internet Search” course.
If you want to learn Internet resourcefulness, then you need to choose a convenient time to take the course and sign up (just click on the sign up link opposite the convenient time slot at the top of the page)!
After registration, you will still have time to think and make a final decision. By the way, you can meet