What is uri. What is a URL address and how to work with it. Letters from “government organizations”
You can get lost not only in the forest, but also online. And this may be due to an incorrect path or address leading to the resource. You don't know what a URL is? Then, before embarking on any further journey through virtual space, let's understand the email address system.
What is a URL
URL is a generally accepted standard for recording the address and indicating the location of a resource on the Internet. From English its name ( Uniform Resource Locator) is translated as a unified resource locator. You can find an earlier decoding of the abbreviation URL - Universal Resource Locator (universal resource locator). But both meanings complement the concept of URL rather than contradict each other.
The basic format for writing a URL structure looks like this:
://:@:/?#
- most often we mean the protocol.
login – user login used for authorization on the resource.
password – user password for authorization.
host – domain name of the host.
port – host port used during connection.
URL is the path where the requested resource is located on the server.
parameters and anchor– the value of variables and identifier on a specific resource.
Passing variable values in a query string is only possible using the GET method.
Let's look at the URL format of the page of the requested resource using practical examples. On the client side, the URL is displayed in the browser's address bar:
The most common options are:
- http:// ru.wikipedia.org/wiki/Main_page– HTTP is used to transmit the request ( hypertext transfer protocol);
- https://ru.wikipedia.org/wiki/Home_page— https is used as the transmission method. Is a secure form of the http protocol that uses encryption (SSL or TLS);
- fttp://wikipedia.org/wiki/file.txt– file transfer protocol fttp;
- http://mail.ru/script.php?num=10&type=new&v=text– passing variable values in a query string using the GET method.
Any URL format is primarily a character string. It may include:
2; Letters.
2; Arabic numbers (0-9).
2; Reserved characters (“+”, “=”, “!” and others).
2; Special characters – we’ll look at them in more detail.
Using special characters in URLs
Of course, such overly “special” characters are not used in URLs. But there are a few:
- ? – serves to separate a block with transmitted parameters in the request line;
- & - separates passed parameters from each other;
- = — separates a variable in a parameter from its value;
- : - serves to separate the protocol from the rest of the URL;
- # - the symbol is used in the local part of the address. Allows you to access a specific part of the requested page;
- @ - indicated in user registration data and when transferring data using the mailto protocol.
But all this is just a theory. So before we learn the rest, let's look at a small practical example.
A good example
Let’s take this one for clarity simple form registration:
Here is its code:
Registration form
In the first line at the beginning of the form, we specified a handler file (php) for it and a method for transmitting data via the server URL:
Now here is the code for the handler file (1.php):
Your Nick:".$_GET["nick"]."
"; echo "Your age:".$_GET["age"]."
"; ?>We will enter the data into the form and send it to the server for processing. This is what we get in the end:
Pay attention to the URL format in the address bar in the first screenshot. After entering the data and clicking on the “Submit data” button, the values of all fields are sent to the server for processing. And we are redirected to page 1.php, where the handler code is located.
Before you look at the processing result, take a look at the address bar in the second picture. It displays the values of fields passed for processing using the GET method.
In order to hide the data sent to the server, it is used POST method. Then the above URL will look like this:
http://localhost/home/1.php.
Format of URL addresses on websites
Most often, websites use a tree-based URL system. That is, the correct URL consists of several nested elements, the last of which is the desired web page.
For clarity, let’s take a specific URL, which is one of the branches of our site address:
https://www..html
Let's break it down piece by piece:
- www.site – this part is domain name site. If you type it in the address bar of your browser, it will take you to the main page of the site. In most cases this is the index. html ;
- templates – this part of the address points to a specific section of the site. In our case, this is the templates section;
- page_2.html – is the final element of the URL leading to the web page of the thematic section of the resource.
Most often, the URLs of the main sections fully display the site map. But not everything is so simple with redirects on sites deployed on the basis of popular engines (CMS).
Features of URL construction in WordPress
In WordPress, as in any engine built on PHP, all pages of the site are generated dynamically. That is, one part is taken from one template, the other is generated “on the fly” based on several... But such volatility has one significant drawback - the presence of pieces of passed parameters in the URL.
Moreover, this infringes not only on the aesthetic component of the address display, but is also perceived ambiguously by search engines. And this can negatively affect website promotion:
Therefore, it is better to use clean URLs on your website. But where can you get them if the CMS system does not provide the ability to edit them?
Clean URLs are addresses that do not contain passed parameters (in the case of WordPress, database query elements), but only the path to the document. That is, https://www..html is an example of a clean URL.
The easiest way to customize URL display in WordPress is to use specialized plugins.
Disputes on this issue - how to write a URL correctly, with or without a slash at the end? - have been and will be. The arguments are varied and often contradictory. And the penalty for incorrectly recording a universal resource locator (URL) is imagined to be of two types. On the part of search engines, these are supposedly penalties for duplicate pages. From a performance point of view, this is supposedly an unnecessary redirect to the correct post page, automatically generated by the server.
However, when analyzing the technical specifications of Internet standards, in particular the document "RFC 1738 - Uniform Resource Locators (URL)", we have to admit that both options for recording the address of a web resource are formally correct, and the sanction for using one or another option is nothing more than an oddity search engine or tales of pseudo-SEO people.
From the point of view of brevity, the option without a slash at the end seems more correct, regardless of whether your link addresses a “file” on the server or a “folder”, indirect evidence of which will be demonstrated below. But there is not a single statement in the document that another option is incorrect or refers to a completely different resource.
I won’t bore you with a multi-page translation of the mentioned RFC, since, firstly, the purpose of the question was the slashes at the end of the URL, and secondly, the publication is addressed to ordinary users of engines, including those who are not interested in all the details, they are waiting for brief explanations and substantive evidence. Accordingly, I will quote excerpts from this document as evidence and explain. Anyone who is not interested in this can immediately look at the conclusion at the end of the article.
General URL syntax
First of all, I will draw your attention to an excerpt from paragraph 2. General URL Syntax (general URL syntax). In each case, I will provide a fragment of the text in the original language and then a translation into Russian.
URLs are used to `locate" resources, by providing an abstract identification of the resource location. URLs are used to `locate" resources, by providing an abstract identification of the resource location.
That is, the URL itself is a pure abstraction. The fact that it may seem externally similar to the name of a file or folder does not mean at all that it is a physical reference to just such and such a file, and not some other one in the server’s file space. This will be stated explicitly below in the document.
The note In general, with regard to http links, it is fundamentally incorrect to say that, for example,
- http://domain.com/path/subpath/filename.txt- supposedly points to a file
- http://domain.com/path/subpath/- supposedly points to a folder
- http://domain.com/path - allegedly incorrectly points to a folder
We are just used to saying this because it is convenient to associate links with files on the site. In reality, all these links point to some kind of resource, without in any way indicating the type of resource. What is hidden behind each resource, that is, what kind of real file or folder and what type of content will be served via such a link, is already determined by the server configuration.
It is important to understand that in links there is no such thing as “file”, “folder”, “subfolder”, “text”, “image”, “html”, “script”, “style sheet” and so on. No slash at the end or its absence means absolutely nothing until the link undergoes transformation inside the server, and it decides where the link actually points and what type of content is hidden behind it. Only this decision relates to the internal architecture of the server.
Hierarchical schemes
The following is an excerpt from paragraph 2.3 Hierarchical schemes and relative links.
Some URL schemes (such as the ftp, http, and file schemes) contain names that can be considered hierarchical; the components of the hierarchy are separated by "/". Some URL schemes (such as ftp, http, and file) contain names that can be considered hierarchical; Hierarchy elements are separated by the "/" character.
That is, it is argued that in certain address schemes the contents of the resource locator are not forbidden to be implied as hierarchical, and it has not yet been stipulated that the hierarchy is equivalent to any form, say, a file one.
General network diagram syntax
The following is an excerpt from paragraph 3.1. Common Internet Scheme Syntax (common network scheme syntax).
//
The note This, by the way, is an answer to a question derived from the one we are considering. There is often a debate on this issue: what is the correct way to provide a link to a domain (host) - without a slash at the end or with a slash?
How to do it right http://domain.com/ or http://domain.com ?
And so and so is correct. It's just that the first slash after the hostname is intended to separate the pathname from the hostname. The same paragraph of the document reports this as follows:
Url-path The rest of the locator consists of data specific to the scheme, and is known as the "url-path". It supplies the details of how the specified resource can be accessed. Note that the "/" between the host (or port) and the url-path is NOT part of the url-path. The rest of the locator consists of schema-specific data and is known as the "url-path". It provides details on how the specified resource can be accessed. Note that the "/" character between the host (or port) and the URL path is not part of url-path.
There is no word obliging you to put this trailing character or not to put it when the url-path is equal to the empty string (as many of us would say, when the URL links to the root of the site). No one has the right to apply penalties to you “for two takes of the main page,” because according to the specification, in both cases you link the URL to the same resource.
Let's continue another excerpt from the same paragraph.
The url-path syntax depends on the scheme being used, as does the manner in which it is interpreted. The url-path syntax depends on the scheme used, as does the way it is interpreted.
This is further confirmation that each locator scheme has its own concept of “hierarchy” and way of interpreting it.
Hierarchy
For some file systems, the "/" used to denote the hierarchical structure of the URL corresponds to the delimiter used to construct a file name hierarchy, and thus, the filename will look similar to the URL path. This does NOT mean that the URL is a Unix filename. The "/" character is used to denote the hierarchical structure of a URL, corresponding to the delimiter used in constructing the filename hierarchy, and thus on some file systems the filename appears similar to the URL path. But that doesn't mean the URL is a Unix-like filename.Despite the fact that this paragraph applies to the ftp scheme, its statements nevertheless apply to other schemes (http, gopher, prospero, and so on). Only in the file scheme does the slash symbol logically mean the same thing as in file names, for example file://server_or_device/path/subpath/filename.txt.
Http
An HTTP URL takes the form: http://
The note It also states that you can specify a link without a trailing slash. In this case, we were talking about a situation where the link path is empty - it points to the root of the host.
Formal entry
And finally, an excerpt from paragraph 5. BNF for specific URL schemes (formal notation for specific URL schemes).
Optional parts are indicated here in square brackets. An asterisk before a parenthesis denotes 0 or more repetitions of the fragment as indicated in the parentheses. The vertical bar should be understood as OR.
Hostport = host [ ":" port ] ... ... httpurl = "http://" hostport [ "/" hpath [ "?" search ]] hpath= hsegment *[ "/" hsegment ] hsegment = *[ uchar | ";" | ":" | "@" | "&" | "=" ] search = *[ uchar | ";" | ":" | "@" | "&" | "=" ] ... ... lowalpha = "a" | "b" | "c" | "d" | "e" | "f" | "g" | "h" | "i" | "j" | "k" | "l" | "m" | "n" | "o" | "p" | "q" | "r" | "s" | "t" | "u" | "v" | "w" | "x" | "y" | "z" hialpha = "A" | "B" | "C" | "D" | "E" | "F" | "G" | "H" | "I" | "J" | "K" | "L" | "M" | "N" | "O" | "P" | "Q" | "R" | "S" | "T" | "U" | "V" | "W" | "X" | "Y" | "Z" alpha = lowalpha | hialpha digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" safe = "$" | "-" | "_" | "." | "+" extra = "!" | "*" | """ | "(" | ")" | "," hex = digit | "A" | "B" | "C" | "D" | "E" | "F" | "a" | "b" | "c" | "e" | "%" hex unreserved | safe |
Please note how precisely the hpath element - the link path - is formed according to the rules. Elements of the hsegment path - segments - are separated by a slash. As if hinting at the important idea that the slash divides the path into hierarchical parts and is always located inside. In principle, it is possible that the last hsegment element may be empty line(this follows from its definition), and then a closing slash involuntarily appears at the end of the URL.
Conclusion
Dividing a path into segments using the slash character implies the presence of non-empty names for these segments. Accordingly, a link with a slash at the end seems illogical (although not prohibited) in the sense that it seems to point to some final segment of the path, but does not name this segment in any way. Just like the link is illogical (but also not prohibited) http://domain.com/level1////levelX, which does not name intermediate path segments if the path is considered not as a set of parameters, but as a hierarchical structure.
In colloquial language, the semantic content of the two links can be explained as follows:
- - addresses to the default starting point of the second level of the hierarchy
- - addresses to an undefined point within the second level of the hierarchy, that is, it is as if the server is entrusted with the task that “we are addressing the second level of the hierarchy, and you yourself determine which point in this level you consider to be the default initial one.”
From everything said above it follows, which is the same as links
- http://domain.com
- http://domain.com/
address the visitor to the root of the site, and for example links
- http://domain.com/level1/level2
- http://domain.com/level1/level2/
address the visitor to the second level of the resource hierarchy. And the fact that a certain server can interpret the slash at the end in its own way and begin to internally redirect to the default starting point of the level - say, to the index.html file, this is already a special case of a specific configuration. Just like in the implementation of a system of human-readable URLs, all redirect records using the mod_rewrite server module define their own (inherent in a specific engine) concept of a hierarchical URL structure, in which path elements can be equated to query parameters and have nothing in common with the file structure of the site ( classic example: http://domain.com/ru/path, the ru element is a parameter of the current language, not a folder on the site).
I would especially like to emphasize that this is internal knowledge of the server, determined by its configuration, as well as the engine installed on the site. An external service, say the same search engine, cannot make conjectures and has no idea whether and how links with and without slashes differ, unless the site server is specially configured so that such links provide different content.
For your information
At the implementation level, the issue of slashes at the ends is not of fundamental importance, which is confirmed by many famous portals. On some, all links end with a slash, on others - without a slash. The main thing is that the content on the links does not turn out to be different, and for Yandex you need to register a 301st redirect from those links that you do not use (say, ending with a slash) to those that you use. The fact is that, according to unconfirmed statements by the Yandex support service, this search engine can allegedly make mistakes and not “glue” (memorize in its knowledge) or with some delay glue slash-without-slash addresses into one.

Here is an example of implementing such a redirect using the root .htaccess file:
# if the input url ends with a slash (em, ami), # set a 301st redirect to a page without a slash RewriteCond %(REQUEST_URI) ^/.+/$ RewriteRule ^(.*?)/+$ http://%(HTTP_HOST )/$1
To Google (again, according to information not confirmed by experiment), these redirects are not important, since it supposedly knows how to glue such addresses correctly and without redirects.
Remember There are many people who consider themselves SEO specialists. But not every one of them is like that. Moreover, the topic of SEO is often speculated on without proper knowledge and grounds, simply in the belief that you are also ignorant in this area, so you will easily believe in any “noodles”. When you are told that one of your pages has “flyed out of the index,” use a very good recommendation from Yandex: You can find out about indexing errors, if any, in the Yandex.Webmaster service. In this service you can always see a list of your pages that are in search and a list of pages excluded from the search for some reason. Google also has a similar service. Trust this knowledge, and not the opinion of pseudo-experts who somewhere heard something out of the corner of their ears, and on that basis recommend that you do what seems to them the only correct thing.
Here Very interesting publication Little-Known SEO Facts, published April 2017. It presents a large study with many screenshots, which began with the goal of testing the validity of several popular judgments in the field of search engine promotion and using clear examples to convey the results to the average website owner. The same study simultaneously demonstrates to the young reader a number of obvious, ordinary, and rather inconspicuous, but still amazing features of organic search results in Google and Yandex searches.
Here Although the following link has almost nothing to do with SEO, it will still be attractive to SEO masters who are now looking for additional orders. A commercial offer is posted under the link; the guys found an interesting way to use the site. Private businesses are offered the creation of an online billboard based on some special theme, under the control of which the site, or rather its first screen, looks like a banner stretch on outdoor advertising billboards. On the smartphone I rotated the screen, the stretch became vertical and occupied the entire screen area, turned it back, it became horizontal and again filled the entire screen. And under the first screen there is a text appendage, where users usually do not scroll, but the search engine sees this text well. So, the smartest pinocchios in regional business buy these inexpensive online billboards as a profitable alternative contextual advertising and the contextual media network of Yandex and Google. And in order to get the maximum exposure in the local search index, they are ready to spend money on a bunch of SEO texts at once to promote their billboard, which smells like quite a bit of money. Judging by rumors, orders for 30 kilo rubles are slipping through, and since the guys outsource them to SEO partners, here you can build partnership bridges and get a good extra income.
Users often have questions about what a file (site) URL is, how to find it out, and what is the value of such details. Our article will provide the necessary answers.
What is a URL
Uniform Resource Locator stands for “web site location locator.” A URL identifier consists of a domain name and a path to a specific page with the name of its file. The inventor of the URL was Tim Berners-Lee, a member of the European Nuclear Warfare Council meeting in Geneva. At the time of its creation in 1990, the site URL was simply the address in the system where the file is located. To find out the site URL, just look in the address bar, and to determine the file address you need to go to context menu by clicking on the corresponding object right button mice. Having many advantages, in particular the accessibility of navigation on the Web, such an address also has a disadvantage - the ability to work exclusively with the Latin alphabet, some symbols and numbers. If it is necessary to use the Cyrillic alphabet, special conversion is carried out.
Types of URLs
Static – does not involve changes on the page.
Dynamic URL - what it is, you can understand if you imagine a search form or other navigation tool in which information is generated depending on incoming requests.
An address with a session ID that is added each time users visit the page.
The importance of URL in SEO promotion
Search engines take into account the keys included in the URL. Most influence on search engine promotion keywords in the domain and subdomains.
If the site address is informative, this also increases the ranking. A search robot will most likely return it in response to a topical query.
The URL that matches the query appears in bold in the search results, attracting additional attention and increasing click-through rates.
: I always wanted to understand this, but its significance was so small that there was always a reason not to do it :)
Have you ever wondered: URL - what is it?
I always come across this, but until now I didn’t want to understand what the difference is between the terms URI, URL, URN, and then suddenly a post (unfortunately, it has already sunk into oblivion), I decided - I’ll read it myself and tell others, although, as stated above, nothing will change from this, but I sometimes like to literalize, so read the sensible translation:
Have you ever noticed the address bar in your browser? What is this? URI, URL or URN? Many of us do not distinguish between URI, URL, URN, and some have not even heard of the terms URI and URN, everyone just uses the term URL. Let's try to figure this out together.
Decoding abbreviations
URI - Uniform Resource Identifier identifier resource)
URL - Uniform Resource Locator (unified location finder resource)
URN - Unifrom Resource Name (unified Name resource)
Attention, the truth is hidden in the details here, but so far nothing is clear, it’s some kind of mess. Let's move on.
Definition
URI: Denotes the name and address of a resource on a network. As a rule, it is divided into URL and URN, so URL and URN are components of URI.
URL: The address of some resource on the web. A URL defines the location of a resource and how it can be accessed.
URN: The name of some resource on the web. The point of a URN is that it defines only the name of a specific item, which can be found in many specific places.
There's nothing better than a concrete example
URI = http://site/2009/09/uri-url-urn.html
URL = http://site
URN = /2009/09/uri-url-urn.html
Let's sum it up
URI is the concept of an abstract identifier, whereas URL and URN are the concrete implementation of an address and a name.
I hope everything is clear to everyone. Be literate!
The perception of each of us is individual, so argue and read the discussions in the comments to the article, there is a lot of interesting stuff there.
According to various sources, from 50 to 95% of all emails in the world - spam from cyber fraudsters. The goals of sending such letters are simple: to infect the recipient’s computer with a virus, to steal user passwords, to force a person to transfer money “to charity”, to enter personal data bank card or send scans of documents.
Often spam is annoying at first glance: crooked layout, automatically translated text, forms for entering a password right in the subject line. But there are malicious letters that look decent, subtly play on a person’s emotions and do not raise doubts about their veracity.
The article will talk about 4 types of fraudulent letters that Russians most often fall for.
1. Letters from “government organizations”



Fraudsters can pretend to be the tax office, Pension Fund, Rospotrebnadzor, sanitary and epidemiological station and other government organizations. For credibility, watermarks, scans of seals and state symbols are inserted into the letter. Most often, the task of criminals is to scare a person and convince him to open a file with a virus attached.
Usually this is an encryptor or a Windows blocker that disables the computer and requires you to send a paid SMS to resume operation. A malicious file can be disguised as a court order or a summons to appear before the head of the organization.
Fear and curiosity turn off the user's consciousness. Accounting forums describe cases where employees of organizations brought files with viruses to their home computers because they could not open them in the office due to the antivirus.
Sometimes scammers ask you to send documents in response to a letter in order to collect information about the company, which will be useful for other deception schemes. Last year, one group of scammers was able to deceive many people using the "request to fax papers" distraction trick.
When an accountant or manager read this, he immediately cursed the tax office: “There are mammoths sitting there, oh my!” and switched my thoughts from the letter itself to the solution technical problems with shipping.
2. Letters from “banks”


Windows blockers and ransomware can hide in fake letters not only from government organizations, but also from banks. Messages “A loan has been taken out in your name, please read the lawsuit” can really be scary and make you want to open the file.
A person can also be persuaded to enter a fake Personal Area, offering to see accrued bonuses or receive a prize that he won in the Sberbank Lottery.
Less often, scammers send invoices for payment of service fees and additional interest on the loan, for 50-200 rubles, which are easier to pay than to understand.
3. Letters from “colleagues”/“partners”
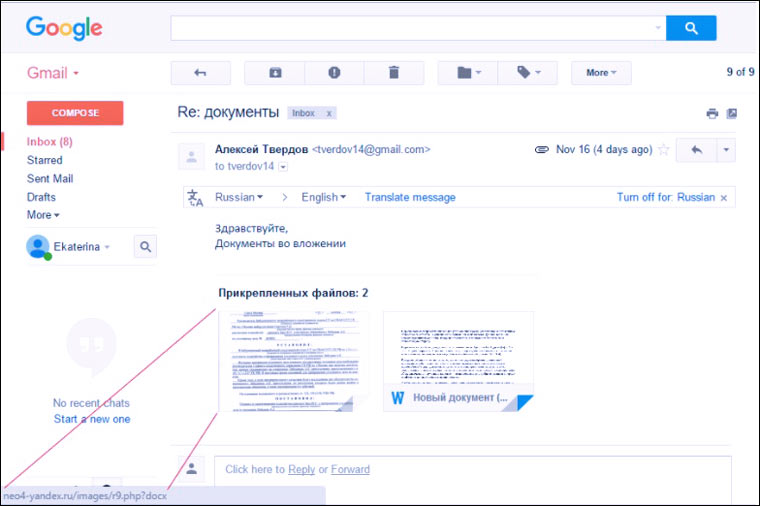
Some people receive dozens of business letters with documents during the working day. With such a load, you can easily fall for the “Re:” tag in the subject of the letter and forget that you have not yet corresponded with this person.
Especially if the poisoner field indicates “Alexander Ivanov”, “Ekaterina Smirnova” or any simple Russian name, which absolutely do not linger in the memory of a person who constantly works with people.
If the goal of scammers is not to collect SMS payments for unlocking Windows, but to cause harm to a specific company, then letters with viruses and phishing links can be sent on behalf of real employees. The list of employees can be collected on social networks or viewed on the company website.
If a person sees a letter in the mailbox from a person from a neighboring department, then he does not take a closer look at it, he may even ignore antivirus warnings and open the file no matter what.
4. Letters from “Google/Yandex/Mail”
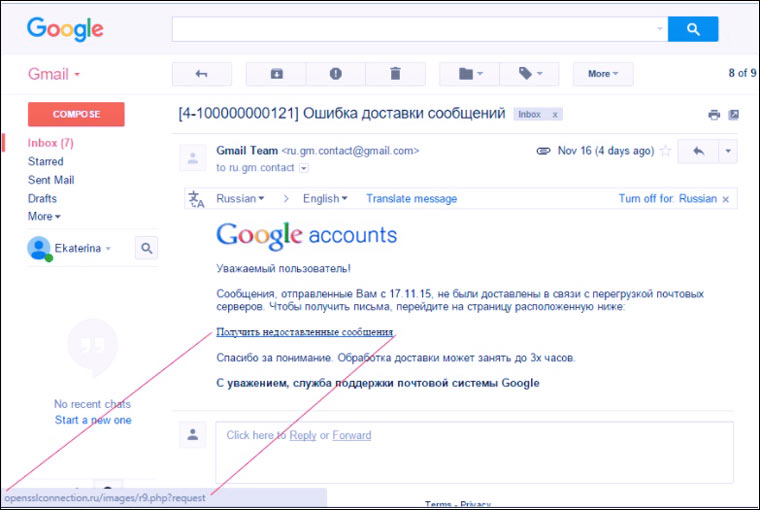
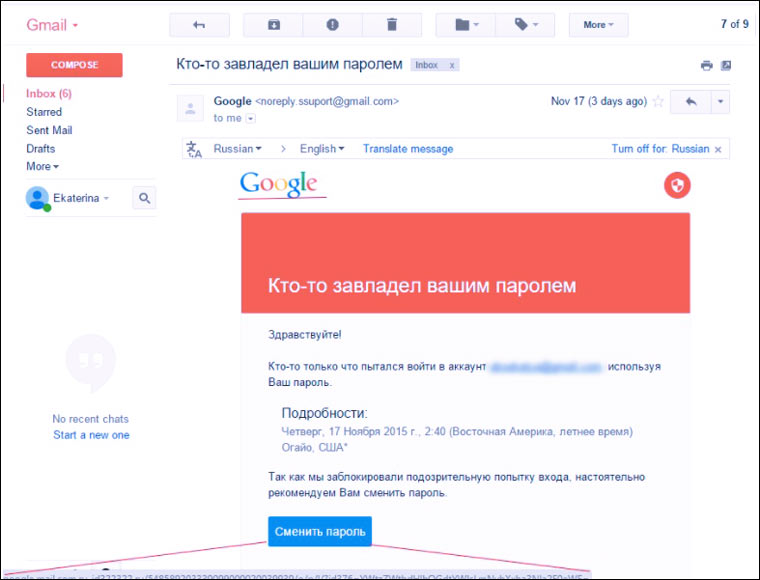
Google sometimes sends emails to Gmail account owners saying that someone has tried to log into your account or that you've run out of space. Google Drive. Fraudsters successfully copy them and force users to enter passwords on fake sites.
Users of Yandex.Mail, Mail.ru and others also receive fake letters from the “service administration” postal services. The standard legends are: “your address has been added to the blacklist”, “your password has expired”, “all emails from your address will be added to the spam folder”, “look at the list of undelivered emails”. As in the previous three points, the main weapons of criminals are fear and curiosity of users.
How to protect yourself?

Install an antivirus on all your devices so that it automatically blocks malicious files. If for some reason you do not want to use it, then check all even slightly suspicious email attachments for virustotal.com
Never enter passwords manually. Use password managers on all devices. They will never offer you password options to enter on fake sites. If for some reason you do not want to use them, then manually enter the URL of the page on which you are going to enter the password. This applies to all operating systems.
Wherever possible, enable password confirmation via SMS or two-factor identification. And of course, it is worth remembering that you cannot send scans of documents, passport data or transfer money to strangers.
Perhaps many of the readers, when looking at the screenshots of the letters, thought: “Am I a fool to open files from such letters? You can see from a kilometer away that this is a setup. I won't bother with a password manager and two-factor authentication. I'll just be careful."
Yes, most fraudulent emails can be detected by sight. But this does not apply to cases when the attack is aimed specifically at you.
The most dangerous spam is personal

If a jealous wife wants to read her husband’s mail, Google will offer her dozens of sites that offer the service “Hacking mail and social network profiles without prepayment.”
The scheme of their work is simple: they send a person high-quality phishing letters that are carefully composed, neatly laid out and take into account personal characteristics person. Such scammers sincerely try to hook a specific victim. They find out from the customer her social circle, tastes, and weaknesses. To develop an attack on specific person It may take an hour or more, but the effort pays off.
If a victim is caught, they send the customer a screenshot of the mailbox and ask them to pay (the average price is about $100) for their services. After receiving the money, they send you the password for the mailbox or an archive with all the letters.
It often happens that when a person receives a letter with a link to the file “Video compromising evidence on Tanya Kotova” ( hidden keylogger) from his brother, he is filled with curiosity. If the letter is provided with text containing details that are known to a limited circle of people, then the person immediately denies the possibility that his brother could have been hacked or that someone else is pretending to be him. The victim relaxes and turns off the antivirus to hell to open the file.
Not only jealous wives, but also unscrupulous competitors can turn to such services. In such cases, the price tag is higher and the methods are more subtle.
You should not rely on your attentiveness and common sense. Let an emotionless antivirus and password manager protect you, just in case.
P.S. Why do spammers write such “stupid” letters?
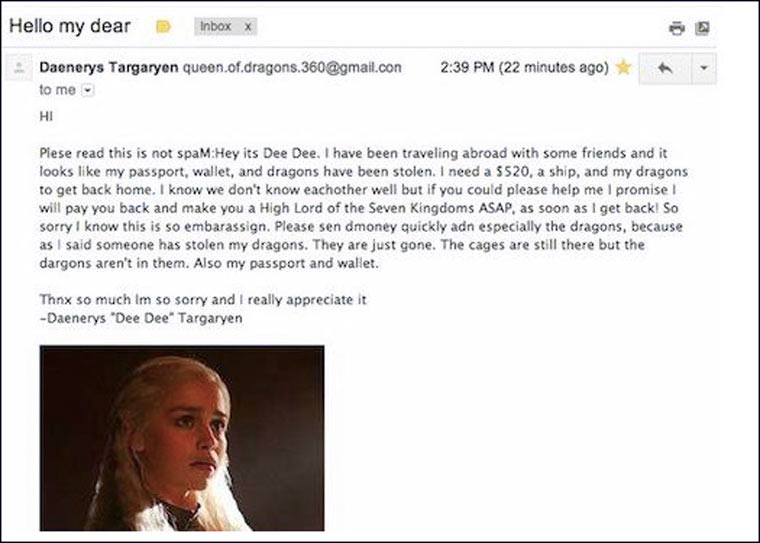
Carefully crafted scam emails are relatively rare. If you go to the spam folder, you can have a lot of fun. What kind of characters do scammers come up with to extort money: the director of the FBI, the heroine of the series “Game of Thrones”, a clairvoyant who was sent to you by higher powers and wants to tell you the secret of your future for $15 dollars, a killer who was ordered to pay you off, but he sincerely offers to pay off .
An abundance of exclamation marks, buttons in the body of the letter, a strange sender address, a nameless greeting, automatic translation, gross errors in the text, obvious overkill of creativity - letters in the spam folder simply “scream” about their dark origin.
Why do scammers who send their messages to millions of recipients not want to spend a couple of hours composing a neat letter and spare 20 bucks for a translator to increase the response of the audience?
In a Microsoft study Why do Nigerian Scammers Say They are from Nigeria? the question “Why do scammers continue to send letters on behalf of billionaires from Nigeria when the general public has known about “Nigerian letters” for 20 years” is deeply analyzed. According to statistics, more than 99.99% of recipients ignore such spam.